As you may know, the new GRCh38 assembly for human was released in December 2013. This is a major update for Ensembl and will require months of hard work to provide high quality annotation for our users. Our goal is to provide a full genebuild on the GRCh38 assembly, as well as regulation, comparative and variation features.
As part of the Ensembl core team, I am responsible for generating a reliable mapping between the GRCh37 and GRCh38 assemblies. This mapping will be used by other teams to project existing annotations onto new coordinates. Therefore, it is important to get this right if we don’t want to end up with features in the wrong location!
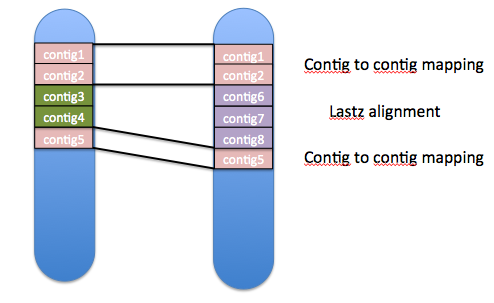
The basic principle of assembly mapping is relatively simple. Let’s say we are mapping chromosome 1 in GRCh37 to chromosome 1 in GRCh38. For both chromosomes, we get the list of contigs used to construct the chromosome. If the same contigs are used, in the same order, in both chromosomes, these can be mapped directly. For the remaining unmapped regions, where no shared contigs can be found, the sequences are aligned using lastz.

Results of the mapping: how similar are the assemblies?
Faced with the results, the mapping meets our expectations. For the 24 chromosomes as well as haplotype regions, we map between 95 and 100% of the non-N sequence. Out of 82 regions, 72 map over 99%. To check the consistency of these mappings, the Ensembl gene set (GENCODE) is copied from GRCh37 to GRCh38. 97% of the transcripts find an identical model in GRCh38, with 98.5% of exons mapped correctly. Only 1.5% of the total transcripts do not have an equivalent model in the new assembly. This is expected, as we know some regions in GRCh37 do not exist in GRCh38.
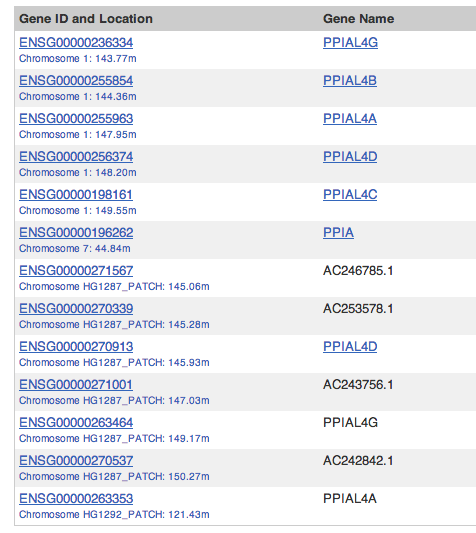
For example, the gene PPIAL4A, associated to CCDS30835.1, is on a reference region in GRCh37 which is overlapped by patch HG1287. In GRCh38, that region does not exist and PPIAL4A is lost. The PPIAL is a family of retrogenes and other PPIAL4 models will still be in GRCh38.

Two additional regions have proved challenging for our mapping.
Chromosome 17:22904289-37003842:
This region in GRCh37 has become a haplotype in GRCh38 (HSCHR17_1_CTG4). As we do not provide mappings between haplotypes, we have only an approximate alignment between the reference in GRCh37 and the reference in GRCh38.
Chromosome 9:42900000-66450000, flanking the centromeric region:
This region in GRCh37 corresponds to 9:40700000-61600000 in GRCh38 and has undergone some massive changes on a sequence level. Some of the contigs have been split, shortened, extended, or simply removed. This means that gene models located on this region will change considerably from the gene models in GRCh37.
If your favourite gene is not in one of these regions though, there is a good chance you will be able to identify it using the same stable_id as in release 75! You’ll be able to read more about stable id mapping in a future post in this series.
Challenge: Patches
One of the major challenges when mapping GRCh37 to GRCh38 comes with patch regions. Shortly after GRCh37 was first released, a number of sequence differences were noticed. Rather than provide a whole new assembly, the concept of patches was introduced.
For regions where a sequencing error was corrected, a patch fix was added. It contains the corrected reference sequence as well as some padding on both ends, to locate it onto the genome.
In Ensembl, we provide annotation for both the reference and the patch region. Where the modified sequence is relatively short, a number of annotations are identical between the reference and the patch.
For example, CHAMP1 is a merged gene on chromosome 13 but has also been annotated on patch HG531_PATCH.


For regions where an alternative sequence was found, a patch novel is added.
In GRCh38, all patch novels will still exist as haplotypes. For the patch fix, it is another story altogether. Given these patches are fixing an error in the reference sequence in GRCh37, they will become the reference in GRCh38, replacing the GRCh37 sequence. This means that we are likely to keep the annotation produced on patches in GRCH37 while losing the GRCh37 reference annotation.
To deal with the special patch cases, we add an additional step in the assembly mapping. For patch fixes in GRCh37, we know their contig composition, as well as where they are mapped against the reference. Presuming the contig composition has not changed, we should be able to locate the same region in the reference in GRCh38. It should then be possible to map any feature in GRCh37, whether on patch or reference, onto GRCh38.